Diff-A-Riff: Musical Accompaniment Co-creation via Latent Diffusion Models
This is the accompanying website to “Diff-A-Riff: Musical Accompaniment Co-creation via Latent Diffusion Models”.
System’s Overview
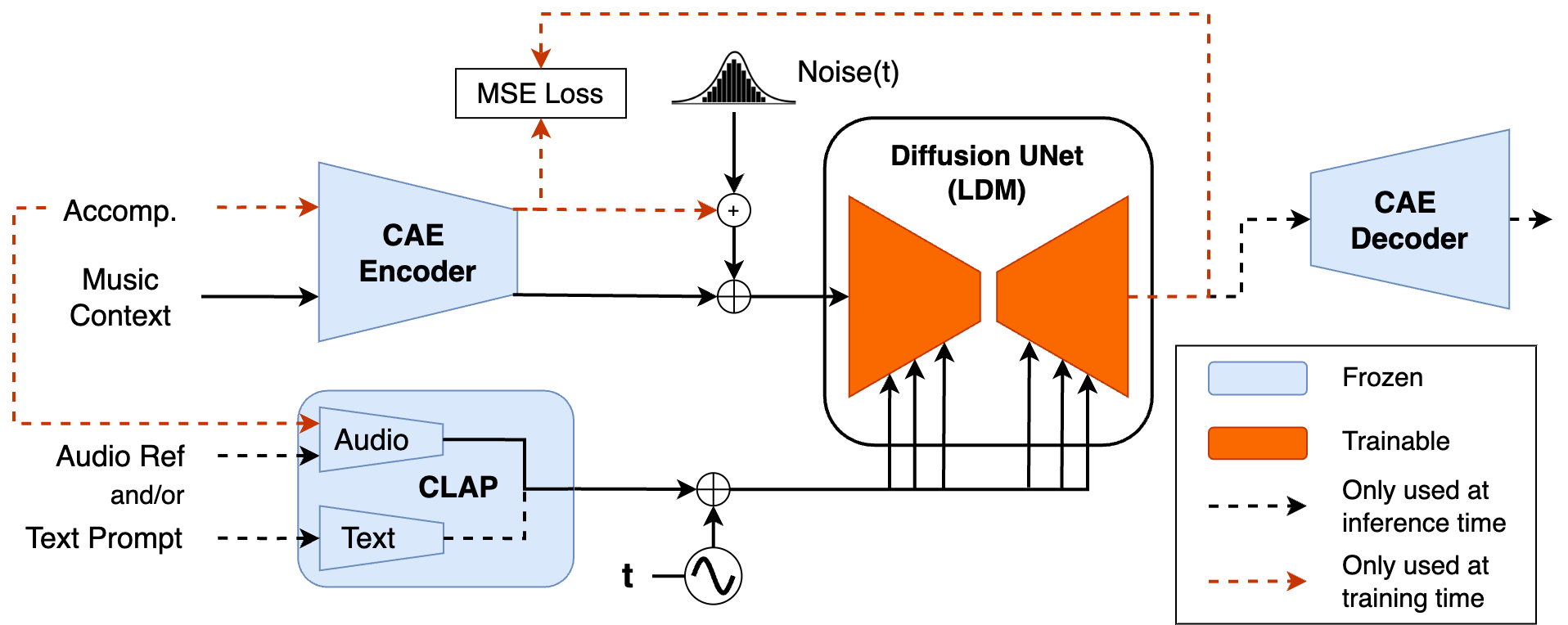
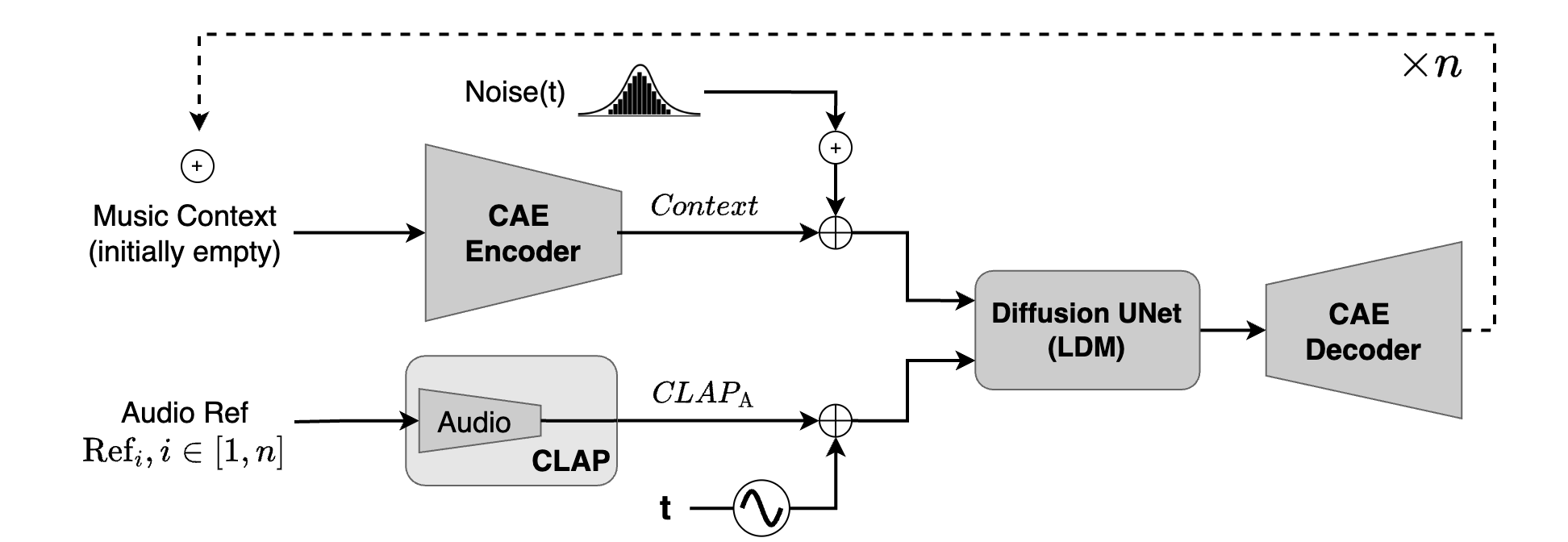
In this work, we introduce Diff-A-Riff, a Latent Diffusion Model capable of generating instrumental accompaniments for any musical audio context.
Our approach relies on a pretrained consistency model-based Autoencoder (CAE) and we train a generative model on its latent embeddings. The proposed generative model is a LDM following the framework of Elucidated Diffusion Models (EDMs). The architecture follows DDPM++, an upgraded version of the originally proposed Diffusion Probabilistic Model.
Given a pair of input context and target accompaniment audio segments, the model is trained to reconstruct the accompaniment given the context and a CLAP embedding derived from a randomly selected sub-segment of the target itself. At inference time, Diff-A-Riff allows to generate single instrument tracks under different conditioning signals.
- First, a user can choose to provide a context, which is a piece of music that the generated material has to fit into. If provided, the context is encoded by the CAE to give a sequence of latents that we call \(\textit{Context}\). When a context provided, we talk of accompaniment generation instead of single instrument generation.
- Then, the user can also rely on CLAP-derived embedings to further specify the material to be generated. CLAP provides a multimodal embedding space shared between audio and text modalities. This means that the user can provide either a music reference or a text prompt, which after being encoded in CLAP give \(\textit{CLAP}_\text{A}\) and \(\textit{CLAP}_\text{T}\) respectively.
Sound Examples
In this section, we demonstrate the generation abilities of our model under different conditioning signals. When no detail is provided, the generations are computed using \(\text{CFG}_\textit{Context} = \text{CFG}_\textit{CLAP} = 1.25\), \(T=30\) diffusion steps and a stereo width \(s_\text{Stereo}=0.4\) .
Accompaniment Generation : a context is provided
In this section, we demonstrate the ability of Diff-A-Riff to generate accompaniments, single tracks that fit a pre-existing context.
With Audio CLAP
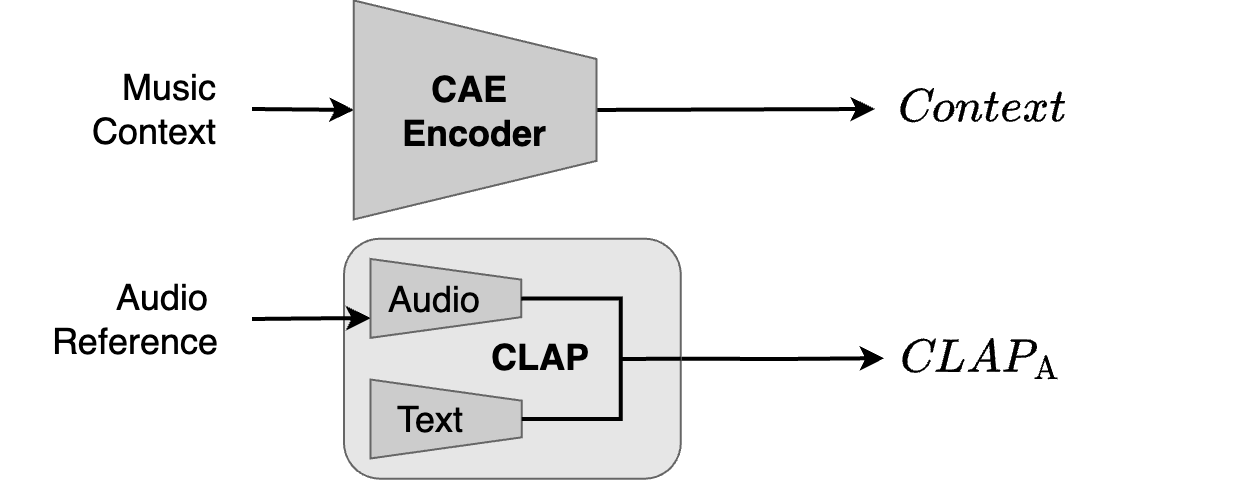
Diff-A-Riff allows the generation of accompaniments based on an audio reference. This represent conditioning on \(\textit{CLAP}_\text{A}\) and \(\textit{Context}\), and is equivalent to the training setup. Here, we present various context music pieces and various audio-based accompaniments.
| Context | Audio Reference | Accompaniments | ||
|---|---|---|---|---|
| 1 | ||||
| 2 | ||||
| 3 | ||||
1 : James May - If You Say, from the DSD100 Dataset [2]
2 : Sambasevam Shanmugam - Kaathaadi, from the DSD100 Dataset
3 : Melody loop by DaveJf, from FreeSound
With Text CLAP
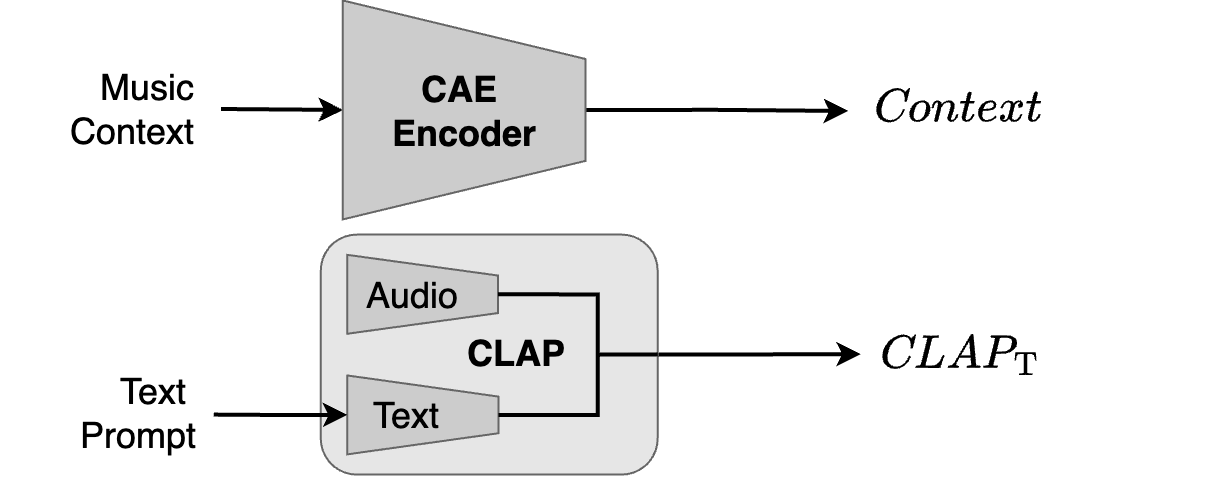
Diff-A-Riff also allows to specify the accompaniment using a text prompt. This represents conditioning on \(\textit{CLAP}_\text{T}\) and \(\textit{Context}\). Here, we present various context music pieces and various text-based accompaniments.
| Context | Text Prompt | Accompaniments | ||
|---|---|---|---|---|
| 3 | "A solo ukulele delivering a cheerful and sunny accompaniment." | |||
| "A mellow synthesizer playing ethereal pads." | ||||
| 4 | "Drums with reverb and a lot of toms." | |||
| "Drums with reverb and a lot of hats/cymbals." | ||||
3 : Fergessen - Back From The Start, from the DSD100 Dataset
4 : Leaf - Come Around, from the DSD100 Dataset
Context-only, no CLAP
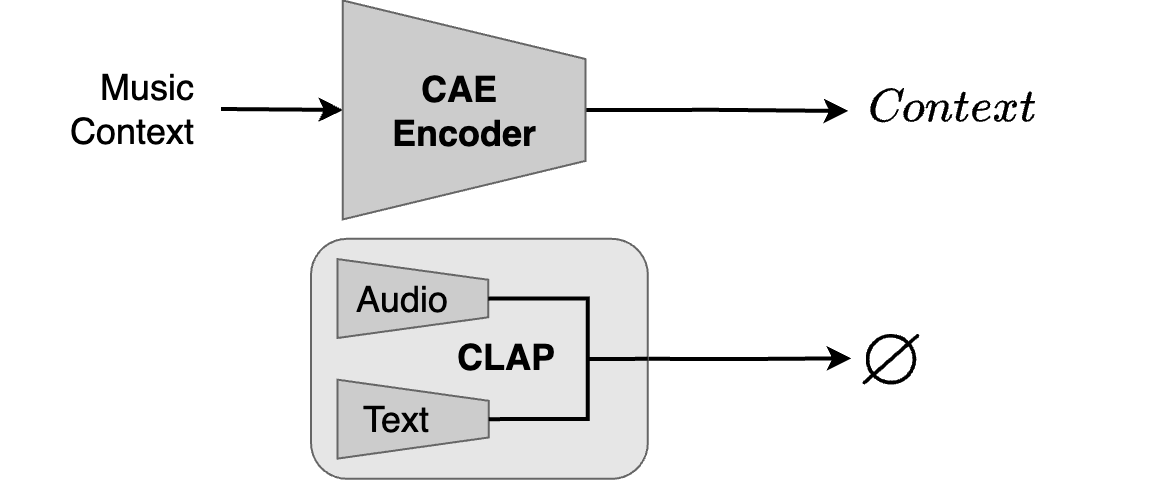
The model can generate accompaniments from a context only, without the need for CLAP embeddings (\(\textit{Context}\) only).
| Context | Accompaniments | |||
|---|---|---|---|---|
Complete Music Excerpts
Despite Diff-A-Riff generating only solo instrumental tracks, we are able to generate multi track music pieces. Starting from an ensemble of \(n\) audio references from the evaluation set and an empty context, we iteratively generate new tracks which are summed into the context to condition the next iteration. After \(n\) iterations, the initially empty context has become a full mix. Here you can find excerpts of multitrack music generated this way.
Single Track generation : no context is provided
Diff-A-Riff also allows the generation of solo instrument tracks without a context. We then refer to it as single track generation, rather than accompaniment.
With Audio CLAP
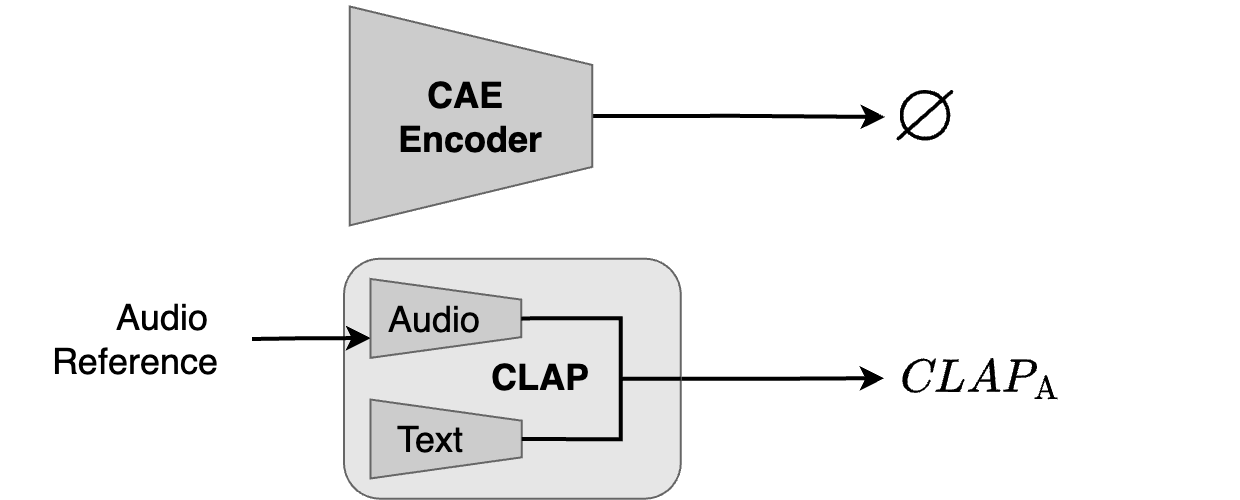
Diff-A-Riff also allows the generation of solo instrument tracks conditioned on audio only (\(\textit{CLAP}_\text{A}\) only).
| Audio Reference | Generations | ||
|---|---|---|---|
With Text CLAP
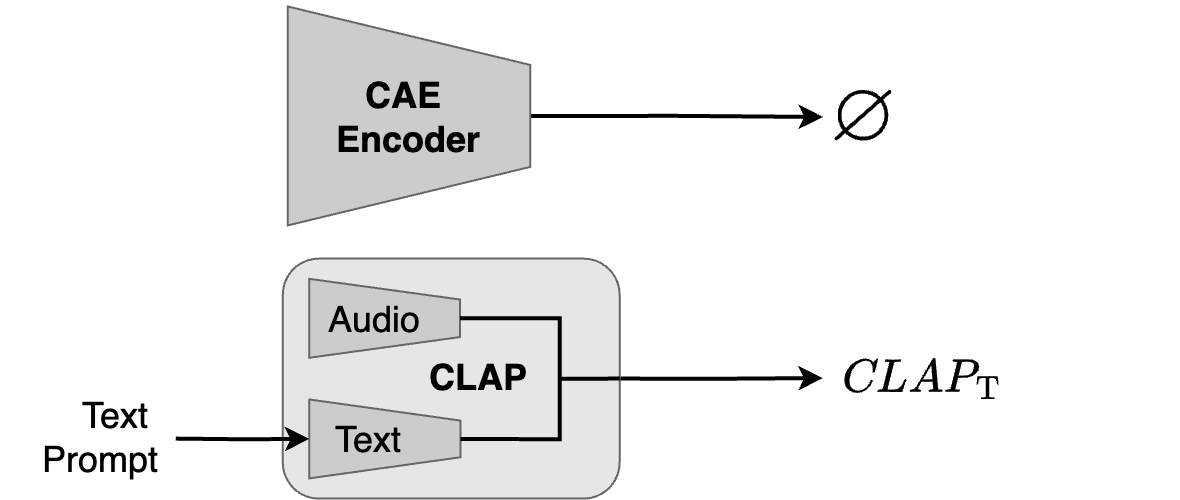
In this section, you can hear single instrument tracks generated solely from a text prompt (\(\textit{CLAP}_\text{T}\) only).
| Text Prompt | Generations | ||
|---|---|---|---|
| "Guitar played folk style." | |||
| "Slow evolving pad synth." | |||
| "A vibrant, funky bassline characterized by the electrifying slap technique, where each note pops with a distinct rhythmic snap and sizzle." | |||
| "A pulsating techno drum beat, where a deep bass kick thunders every quarter note, creating a relentless and hypnotic pulse." | |||
Fully Unconditional
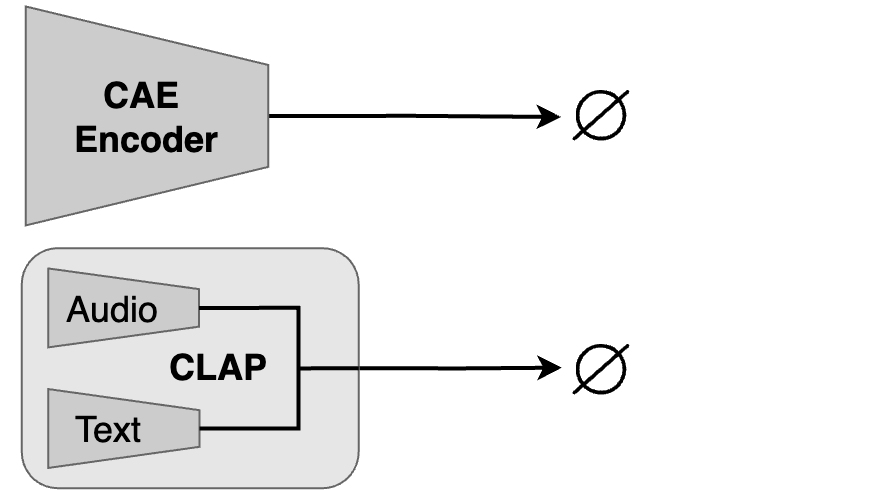
In this section, we show single instrument tracks generated without context or CLAP conditioning.
Bonus
In this section, we demonstrate additional controls derived from the use of a diffusion framework.
Inpainting
As done traditionally with diffusion models, Diff-A-Riff can be used to perform audio inpainting. At each denoising step, the region to be kept is replaced with the corresponding noisy region of the final output, while the inpainted region is denoised normally. This way, we can enforce the inpainted region to blend well with the surroundings.
In line with most diffusion models, Diff-A-Riff allows to perform audio inpainting. During each denoising iteration, the inpainted area undergoes standard denoising, while the region to keep is substituted with its noisy counterpart from the final output. This approach ensures seamless integration of the inpainted section with its surroundings. In the following examples, all tracks are inpainted from second 5 to 8.
| Context | Masked Original Accompaniment | Inpainting w/ Mix | Inpainting Solo |
|---|---|---|---|
Interpolations

We can interpolate between different references in the CLAP space. Here, we demonstrate the impact of a interpolation between an audio-derived CLAP embedding and a text-derived one, with an interpolation ratio \(r\).
| Audio Reference | ||||
|---|---|---|---|---|
| $$ r = 0 $$ | ||||
| $$ r = 0.2 $$ | ||||
| $$ r = 0.4 $$ | ||||
| $$ r = 0.6 $$ | ||||
| $$ r = 0.8 $$ | ||||
| $$ r = 1 $$ | ||||
| Text Prompt | "Latin Percussion" | "Oriental Percussion Texture" | "The Cathciest Darbouka Rhythm" | "Rhythm on Huge Industrial Metal Plates" |
Variations
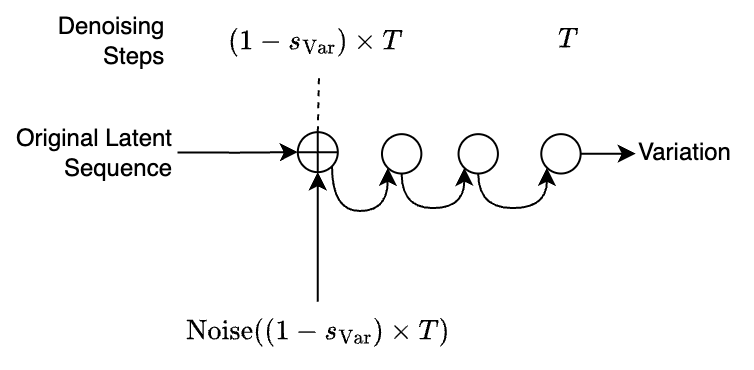
Given an audio file, we can encode it in the CAE latent space and get the corresponding latent sequence. By adding noise to it, and denoising this noisy sequence again, we end up with a variation of the first sequence. We can then decode it to obtain a variation of the input audio. The amount of noise added is controlled through the variation strength parameter \(s_\text{Var}\), which allows to control how different to the original a variation can be.
| Reference | $$s_\text{Var} = 0.2$$ | $$0.5$$ | $$0.8$$ |
|---|---|---|---|
Stereo width
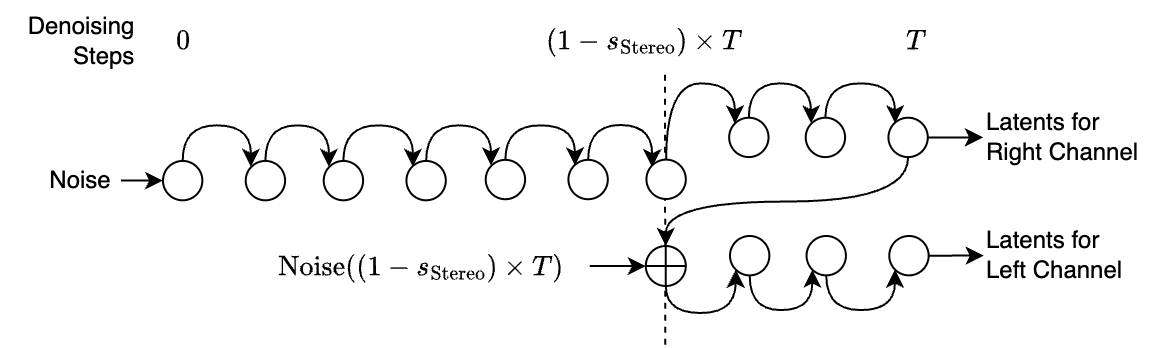
Following the same principle as for variations, for any mono signal, we can create a slight variation of it and use the original and the variation as left and right channels, creating what we call pseudo-stereo. Here, you can find examples of pseudo stereo files, generated from different stereo width \(s_\text{Stereo}\).
| $$s_\text{Stereo} = 0$$ | $$0.2$$ | $$0.4$$ | $$0.5$$ |
|---|---|---|---|
Loop Sampling
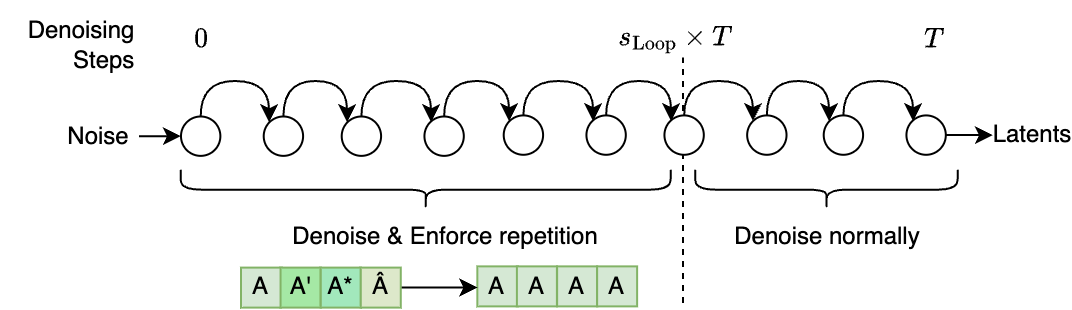
By repeating a portion of the data being denoised, we can enforce repetitions in the generated material. We can enforce this repetition for a fraction \(s_\text{Loop}\) of the diffusion steps, and let the model denoise normally for the remaining last steps to introduce slight variations.
| Number of Repetitions | $$s_\text{Loop}$$ | Generations | ||
|---|---|---|---|---|
| 2 | 0.5 | |||
| 0.8 | ||||
| 1 | ||||
| 4 | 0.5 | |||
| 0.8 | ||||
| 1 | ||||
User Study Sample Questions
Here, you can find examples of the questions participants had to answer in our user studies. The user studies were conducted using the GoListen online platform [1].
Audio Quality Assessment
Here is a link to a demo of the Quality Assessment test.
Subjective Audio Prompt Adherence
Here is a link to a demo of the Subjective Audio Prompt Adherence test.
Ethics Statement
Sony Computer Science Laboratories is committed to exploring the positive applications of AI in music creation. We collaborate with artists to develop innovative technologies that enhance creativity. We uphold strong ethical standards and actively engage with the music community and industry to align our practices with societal values. Our team is mindful of the extensive work that songwriters and recording artists dedicate to their craft. Our technology must respect, protect, and honour this commitment.
Diff-A-Riff supports and enhances human creativity and emphasises the artist’s agency by providing various controls for generating and manipulating musical material. By generating a stem at a time, the artist remains responsible for the entire musical arrangement.
Diff-A-Riff has been trained on a dataset that was legally acquired for internal research and development; therefore, neither the data nor the model can be made publicly available. We are doing our best to ensure full legal compliance and address all ethical concerns.
For media, institutional, or industrial inquiries, please contact us via the email address provided in the paper.
Extra References
[1] Barry, Dan, et al. “Go Listen: An End-to-End Online Listening Test Platform.” Journal of Open Research Software 9.1 (2021)
[2] Liutkus, Antoine, et al. “The 2016 signal separation evaluation campaign.” Latent Variable Analysis and Signal Separation: 13th International Conference, LVA/ICA 2017, Grenoble, France, February 21-23, 2017, Proceedings 13. Springer International Publishing, 2017.