Stochastic Restoration of Heavily Compressed Audio using Generative Adversarial Networks

Sony Computer Science Laboratories Paris
This page contains supplementary material for the manuscript
S. Lattner, J. Nistal, Stochastic Restoration of Heavily Compressed Audio using Generative Adversarial Networks, submitted to MDPI Electronics, Special Issue "Machine Learning Applied to Music/Audio Signal Processing", March 2021
The examples below demonstrate the restoration of MP3 audios in different bit rates (16kbit/s mono, 32kbit/s mono, 64kbit/s mono). In order to ensure a moderate loading time of this website, all files have been saved at 192kbit/s mono. The audio used is for research purposes only, in case a copyright owner wants us to remove protected material, please contact us.
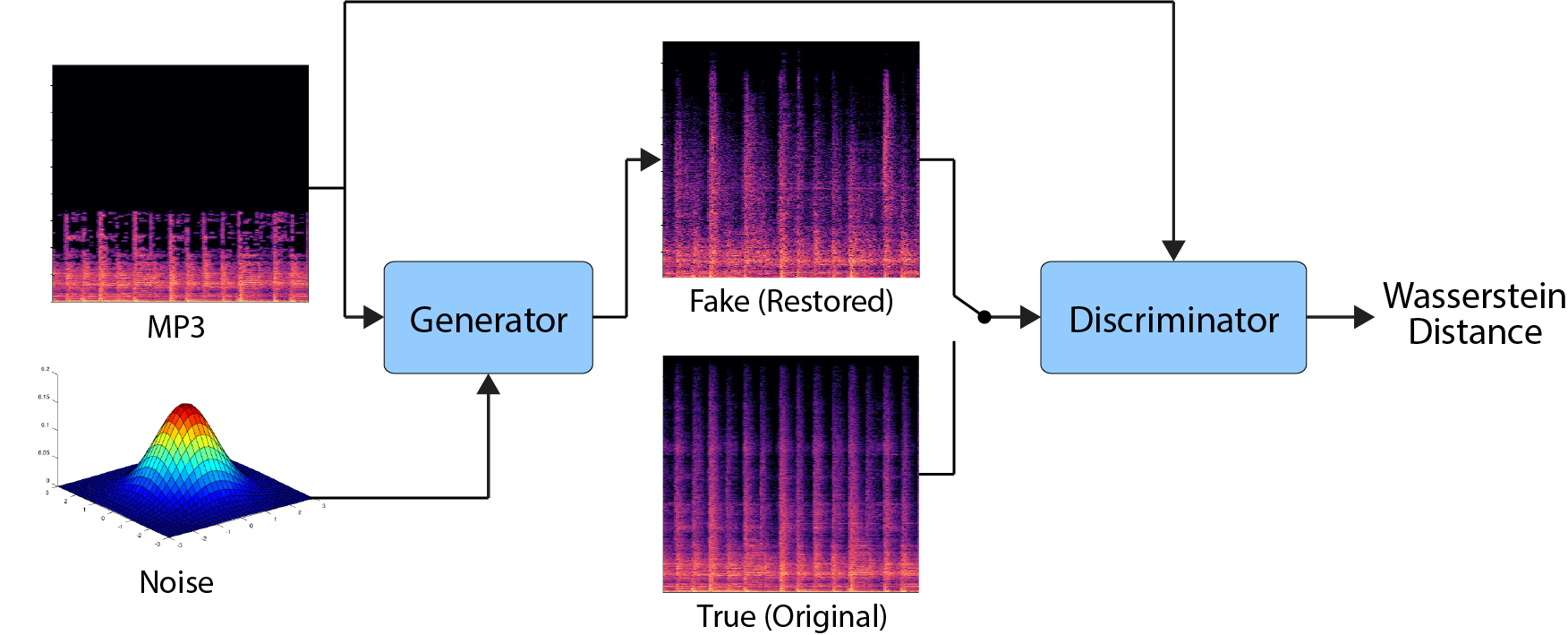
Architecture training:
The examples below are restorations of 32kbit/s MP3s which did not work very well. For example, it is difficult for the model when the input audio is very loud and full, or when there is only voice. In such cases, the added frequencies seem noisy, and also sometimes the model generates percussions on non-plausible positions (examples 1-6). Also, there are (seldomly) some input signals which cause specific distrubances (example 7). Another common problem is that the model sometimes overemphasizes the "s" of a singing voice too much, or causes percussive noise on inappropriate positions (examples 8-10). Such examples lower the perceived quality and led to negative evaluations in the user tests.
| Nr. | Original | MP3 | Generated 1 | Generated 2 | Generated 3 | Deterministic |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | ||||||
| 3 | ||||||
| 4 | ||||||
| 5 | ||||||
| 6 | ||||||
| 7 | ||||||
| 8 | ||||||
| 9 | ||||||
| 10 |
